[YOLO series] p1. Lý thuyết YOLO và YOLOv2
03 Jul 2020 - trungthanhnguyenTrong lĩnh vực computer vision, có rất nhiều chủ đề, bài toán mà con người vẫn đang cố gắng tối ưu: classification, object detection/recognition, semantic segmentation, style transfer… Trong đó object detection là bài toán rất quan trọng và phổ biến, ứng dụng rộng rãi. Ai làm về computer vision không ít thì nhiều cũng phải động tới nó. Khi bạn up ảnh lên facebook, lập tức facebook xác định và gán tên cho từng người trong ảnh. Các camera IP bây giờ đã tích hợp tính năng nhận diện người. Tính ứng dụng của object detection ngày càng thiết thực và mở rộng. Trong bài viết này, mình sẽ viết về YOLO và YOLO_v2

prerequirement: basic knowlegde of deep learning (neural network, convolution…) Note: đón đọc các bài viết của mình tại:
- https://viblo.asia/u/TrungThanhNguyen0502
- https://trungthanhnguyen0502.github.io
- Vietnam AI Link Sharing Community
1. YOLO
1.1 Introduction
Trong phần này, mình sẽ giải thích về phiên bản đầu tiên của YOLO, tức YOLO v1. Trước YOLO đã có rất nhiều ý tưởng và thuật toán cho chủ đề object detection, từ image-processing-based đến deep-learning-based. Trong đó, deep-learning-based cho kết quả tốt vượt trội. Hầu hết các object detection model khi đó được xây dựng theo kiến trúc 2-stage. Nổi bật trong số đó là RCNN, FastRCNN, FasterRCNN. Kiến trúc 2-stage bao gồm 2 giai đoạn:
- Định vị các vùng chứa vật thể
- Đối với từng vùng ở bước 1, tiến hành phân loại.
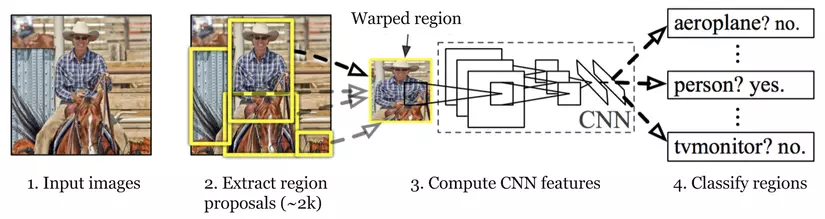
Nguồn ảnh: r-cnn paper
Hướng giải quyết này đảm bảo độ chính xác và chất lượng model khá cao, tuy nhiên lại không đảm bảo về tốc độ và hiệu năng tính toán. Lý do là bởi model bị chia làm 2 giai đoạn (đặc biệt sử dụng ROI Pooling) không thể song song hóa tính toán. Sau này, YOLO xuất hiện giải quyết khá tốt vấn đề này, tính tất cả trong 1 phát :) . Đó chính là ý nghĩa của YOLO - You only look once
1.2 Detail
1.2.1 Architecture
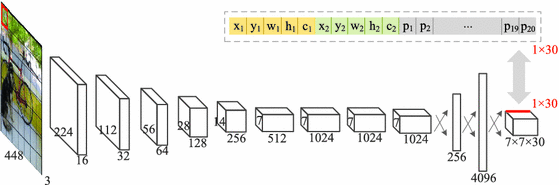
Nguồn ảnh: medium.com
YOLO có kiến trúc khá cơ bản, bao gồm base network và extra layers. Base network là Convolution network có nhiệm vụ trích xuất đặc trưng ảnh. Extra layers là các layer cuối dùng để phân tích các đặc trưng và phát hiện vật thể. Base network thường được dùng là Darknet.
YOLO hoạt động theo cơ chế detect vật thể trên từng vùng ảnh. Ảnh được chia thành S x S ô, ô hay còn gọi là cell … Thực ra là chia trong tưởng tượng, không phải cắt ảnh ra hay thực hiện bất kì bước image-processing nào. Bản chất của việc chia ảnh là việc chia output, target thành dạng matrix $A$ kích thước S x S. Nếu trong ảnh, tâm của vật thể nằm trong cell thứ (i,j) thì output tương ứng nó sẽ nằm trong $A[i,j]$.
Luồng xử lí như sau:
- Convolution network tiến hành trích xuất đặc trưng ảnh
- Extra layers (fully connected layers) phân tích, phát hiện vật thể. Trả về output là một matrix $A$ có kích thước:
\(Shape(A) = S*S*(5*B + C)\) - Trong đó, B là số bound box, mỗi bound box gồm 5 số liệu: (x,y,w,h, confidence_score). confidence score xác suất tại ô đó có object hay không. Cuối cùng là C phần tử - đại diện cho phân bố xác suất về loại object, tức class distribution. Vì C phần tử này là một phân phối xác suất nên cần đảm bảo: \(\sum_0^c p_i = 1\)
Như vậy, bạn đã thấy rằng YOLO tính toán tọa độ bbox, xác suất có xuất hiện vật thể, phân bố xác suất để phân loại vật thể… tất cả đều được thực hiện trong 1 lần. Đó là lý do khiến cho YOLO nhanh hơn nhiều so với các 2-stage model, tạo nên lợi thế cho YOLO.
1.2.2 Loss function
Loss function của YOLO khá đơn giản nếu cần giải thích, nhưng để code lại là một vấn đề khác =))
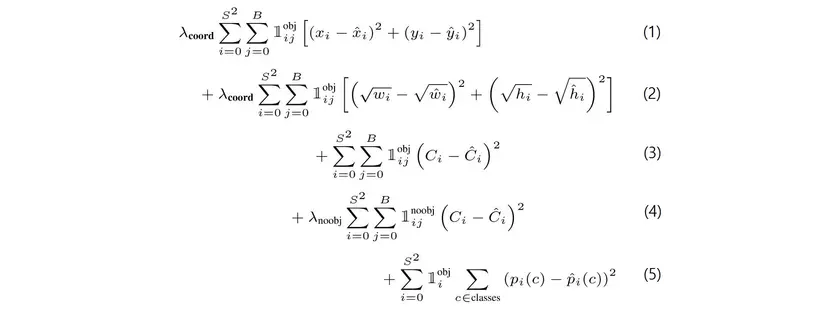
Loss_total được tổng hợp từ 5 phần, mỗi phần nhằm tối ưu một vấn đề riêng biệt:
- p1: xy_loss khi object tồn tại ở $box_j$ trong $cell_i$
- p2: wh_loss khi object tồn tại ở $box_j$ trong $cell_i$
- p3: confidence_loss khi object tồn tại ở $box_j$ trong $cell_i$
- p4: confidence_loss các box không tồn tại object
- p5: class_probability_loss tại cell có tồn tại object.
Chú thích:
- $l_{ij}^{obj}$ = 1 nếu trong ô thứ i, có box thứ j có chứa object.
- $l_{ij}^{noobj}$ ngược lại với $l_{ij}^{obj}$
- $l_{i}^{obj}$ = 1 Nếu ô thứ i có chứa object (ngược lại = 0).
- $\lambda_{coord}$ và $\lambda_{noobj}$ là trọng số thành phần.
1.2.3 Non-max suppression
Giả sử trải qua quá trình huấn luyện mô hình, bạn thu được một model đủ tốt và muốn đưa vào ứng dụng. Tuy nhiên model dù tốt vẫn xảy ra trường hợp: dự đoán nhiều bounding box cho cùng một vật thể

Để giải quyết vấn đề này, ta lọc bớt các bouding box dư thừa ( trùng nhau và cùng class) bằng non-max suppression. Ý tưởng:
- Các box có confidence_score được xếp hạng từ cao xuống thấp. [box_0, box_1, … box_n]
- Duyệt từ đầu danh sách, với từng box_i, loại đi các box_j có IOU(box_i, box_j) > threshold. Trong đó j > i. threshold là một giá trị ngưỡng được lựa chọn sẵn. IOU là công thức tính độ overlap - giao thoa giữa hai bounding box
- Công thức tính IOU được minh họa rất dễ hiểu theo hình:
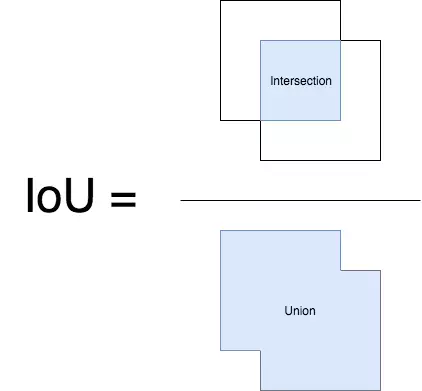
1.3 Conclusion
Vậy trong phần này, bạn đã được cung cấp những kiến thức cơ bản về YOLO phiên bản đầu tiên. Tuy nhiên, YOLO đã phát triển lên phiên bản YOLOv5 với rất nhiều sự thay đổi. Đọc mỗi YOLO là chưa đủ. Sang phần 2, mình sẽ viết về YOLOv2 và cố gắng code nếu có thời gian.
2. YOLO v2
2.1 Introduction
Phần 1, mình đã mô tả chi tiết về YOLO phiên bản đời đầu YOLO v1. Tuy nhiên, YOLO v1 thực sự vẫn tồn tại rất nhiều nhược điểm cần khắc phục:
- Độ chính xác vẫn còn kém so với các Region-based detector.
- Do thiết kế output của YOLO v1, ta chỉ có thể dự đoán tối đa một object trong 1 cell (vì chỉ có một class_distribution cho mỗi cell). Điều đó có nghĩa rằng nếu ta chọn S x S = 7 x 7, số lượng object tối đa chỉ bằng 49. Với những trường hợp nhiều vật cùng nằm trong 1 cell, YOLO sẽ kém hiệu quả.
- (x,y,w,h) được predict ra trực tiếp -> giá trị tự do. Trong khi đó trong hầu hết các dataset, các bouding box có kích cỡ không quá đa dạng mà tuân theo những tỷ lệ nhất định.
YOLO v2 ra đời nhằm cải thiện những vấn đề này.
2.2 Detail
2.2.1 Anchor box
Trước tiên, ta cần đọc một chút về khái niệm anchor box. Thực ra anchor box là ý tưởng của FasterRCNN. Như đã nói, người ta nhận thấy rằng trong hầu hết các bộ dataset, các bbox thường có hình dạng tuân theo những tỷ lệ và kích cỡ nhất định.
Bằng việc dùng Kmean để phân cụm, ta sẽ tính ra được B anchor box đại diện cho các kích thước phổ biến. Dưới đây là minh họa cho cách tính các anchor box đại diện trong 1 bộ dataset.
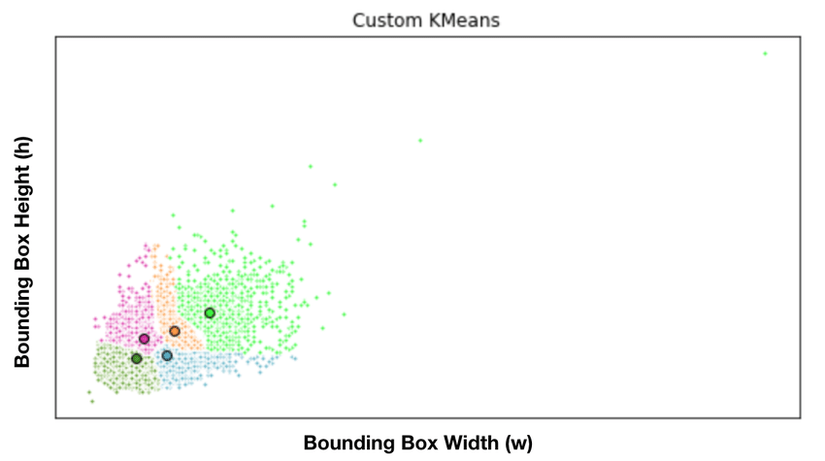
Nguồn ảnh: ResearchGate
Như vậy, thay vì predict trực tiếp (x,y,w,h), ta predict ra bộ offset - tức độ lệch giữa groundtruth_bbox với các anchor box.
2.2.2 Ideal
Các cải tiến của YOLO v2 so với YOLO v1 bao gồm:
- Input image có kích thước lớn hơn bản v1.
- Tận dụng ý tưởng anchor box từ FasterRCNN
- Add thêm các BatchNorm layer vào model
- Bỏ đi các fully-connected ở cuối model, giúp tăng tốc độ tính toán, kích thước ảnh input cũng động hơn
- Thay vì có chỉ một class_distribution chung cho cả một cell, mỗi bounding box đều có class_distribution của riêng nó. Như vậy, một cell có thể đồng thời có nhiều boundbox cho các object khác nhau -> vấn đề multi-object in a cell được giải quyết.
Chính những thay đổi này đã khiến YOLO v2 hiệu quả hơn hẳn, cũng trở thành nền tảng chính để các phiên bản v3, v4, v5 phát triển dựa trên. Dưới đây là hình minh họa output của YOLO v2:
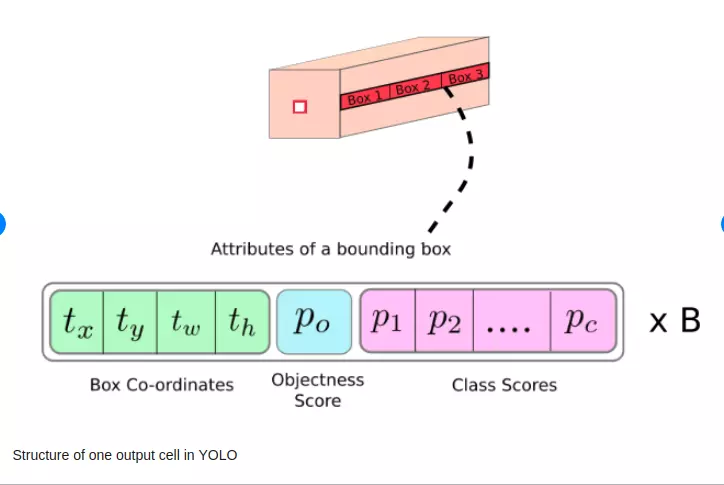
Output and loss function
Output của YOLO v2 là matrix $A$ có shape: \(Shape(A) = S* S* B *( 4 + 1 + C)\)
- Với mỗi bbox ta predict ra: $t_x, t_y, t_w, t_h, p_{object}$, class_distribution $(p_1, p_2… p_c)$.
- Trong đó, $(t_x, t_y, t_w, t_h)$ không phải giá trị thực của bbox, mà chỉ là giá trị offset của bbox so với 1 anchor box cho trước. Anchor box này có kích thước $(p_w, p_h)$ được định nghĩa sẵn
- Từ $(t_x, t_y, t_w, t_h)$, ta cần bước biến đổi để tính ra giá trị tọa độ thật của bbox $(b_x, b_y, b_w, b_h)$ dựa trên $(p_w, p_h)$ theo công thức dưới đây.
- hàm $\sigma(t_x)$, $\sigma(t_y)$, $\sigma(t_o)$ là hàm sigmoid, dùng để ép miền giá trị về khoảng $(0,1)$.
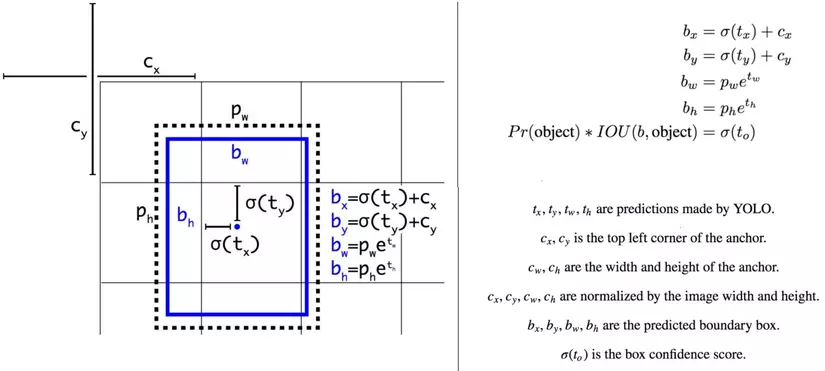
Nguồn ảnh: yolo v2 paper
Loss function, về cơ bản, loss function của YOLO v2 vẫn như vậy, khi code chỉ cần khéo léo khi tính $(b_x, b_y, b_w, b_h)$ một chút là được.
Như vậy, qua bài này bạn đã được cung cấp đủ kiến thức về YOLO/YOLOv2. Trong bài sắp tới, mình sẽ hướng dẫn code lại YOLO v2. Cảm ơn bạn đã đọc bài viết.