[GAN series] p1. GAN cơ bản
10 Jul 2020 - trungthanhnguyen1. Lý thuyết về GAN
1.1 GAN là gì ?
GAN là viết tắt “Generative Adversary Networks”. Generative có nghĩa là sinh ra, Adversary là đối nghịch. Như vậy, ta có thể hiểu là GAN có thể sinh ra dữ liệu mới sau quá trình học dựa trên cơ chế “đối nghịch”. GAN có thể tự sinh ra một khuôn mặt mới, một con người, một đoạn văn, chữ viết, bản nhạc giao hưởng hay những thứ tương tự thế. Thế làm cách nào để GAN học và làm được điều đó, chúng ta cần phải điểm qua một vài khái niệm.
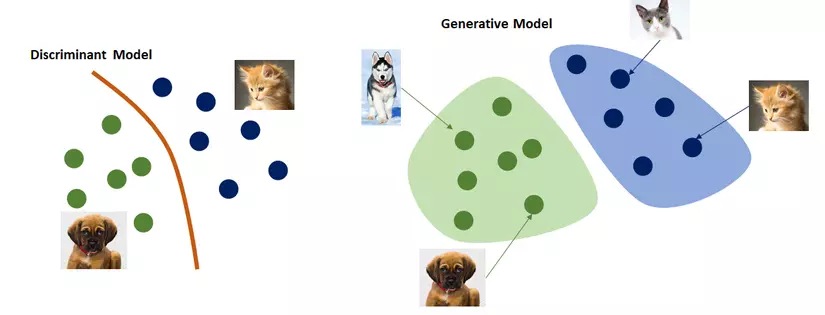
1.1.1 Discriminative model
Trước đây, hầu hết các mạng đều thuộc dạng Discriminative model, tức trải qua quá trình huấn luyện, model đạt được khả năng định vị được vị trí của một điểm dữ liệu trong phân bố dữ liệu (điển hình là bài toán phân loại). Ví dụ: một đứa trẻ được cho xem 1000 ảnh có mèo và 1000 ảnh không mèo (ảnh kèm nhãn có-không). Trải qua quá trình quan sát và học hỏi, đứa trẻ đó sẽ có khả năng phân biệt những ảnh mới xem ảnh nào có, ảnh nào không có mèo. Đó là điển hình cho một “discriminative model”. Các bài toán classify, regression, image semantic segmentation, object detection … bản chất đều liên quan tới “discriminative model”.
nguồn ảnh: https://miro.medium.com
1.1.2 Generative model
Cũng với ví dụ trên, trải qua sau quá trình học liệu đứa bé có thể tự hình dung ra hình ảnh một con mèo hoàn toàn mới. Việc sinh ra ảnh mới đó là việc của “generative model”.
1.2 Thuật toán
Note: Để thống nhất và dễ hiểu, mình sẽ lấy kiểu dữ liệu là ảnh để mô tả thuật toán, các dạng dữ liệu khác như âm thanh, tín hiệu đều tương tự.

GAN được kết hợp từ 2 model: generator G và discriminator D. Cơ chế hoạt động và huấn luyện GAN dựa trên trò chơi minimax, trò cảnh sát tội phạm: tội phạm G tạo ra tiền giả, cảnh sát D học cách phân biệt thật giả và feedback lại cho tội phạm. Cảnh sát càng cố gắng phân biệt tiền thật-giả thì tội phạm lại dựa vào feedback để cải thiện khả năng tạo tiền giả của mình.
Thuật toán:
- B1: Từ một nhiễu z bất kì, G sinh ra fake-image G(z) có kích thước như ảnh thật real-image x. Tại lần sinh đầu tiên, G(z) hoàn toàn là ảnh nhiễu, không có bất kì nội dung gì đặc biệt
- B2: x và G(z) cùng được đưa vào D kèm nhãn thật-giả. Train D để học khả năng phân biệt ảnh thật, ảnh giả.
- B3: Đưa G(z) vào D, dựa vào feedback của D trả về, G sẽ cải thiện khả năng fake của mình.
- B4: Quá trình trên sẽ lặp đi lặp lại như vậy, D dần cải thiện khả năng phân biệt, G dần cải thiện khả năng fake. Đến khi nào D không thể phân biệt được ảnh nào là ảnh do G tạo ra, ảnh nào là x, khi đó quá trình dừng lại.
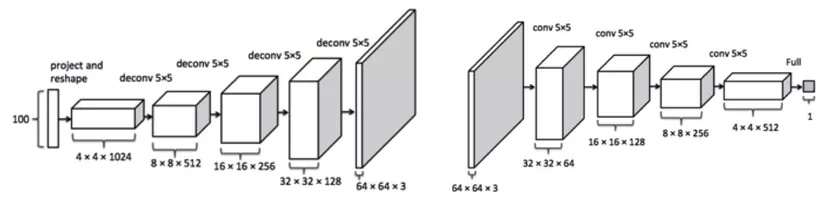
Input cho G là một nhiễu z, được sinh ngẫu nhiên từ một phân phối xác suất (phổ biến nhất là Gaussian). Kiến trúc GAN phổ biến là DCGAN - Deep Convolution GAN: cả G và D là các mạng Convolution nhiều lớp, sâu như hình dưới đây:
1.2.1 Backpropagation
Để train được D, input gồm cả G(z) và x kèm nhãn. Như vậy, mục tiêu của D là maximinze:
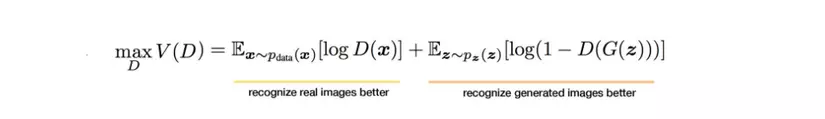
Để train được G, ta dựa vào D(G(z)). Bước này nhằm mục đích update các weight của G sao cho G(z) có thể đánh lừa được D, khiến D đoán nhầm nhãn của G(z) là y = 1. G cố gắng minimize:

Tổng quát lại, D, G là kết quả của quá trình:
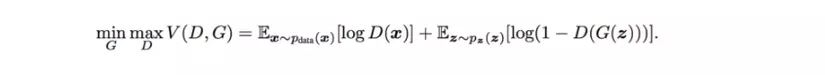
Dưới đây là pseudo code minh họa thuật toán.

1.2.2 Generator diminished gradient
Trong quá trình train, ta dễ gặp phải vấn đề khi gradient cho G. Thường tại những bước đầu, D rất dễ dàng nhận dạng ảnh fake do G tạo ra. Điều đó khiến cho V = -log(1 - D(G(z))) có giá trị xấp xỉ 0. Điều này gây ra hiện tượng gradient vanishing khiến model khó train, khó hội tụ. Để cải thiện, ta thay đổi công thức 1 chút:
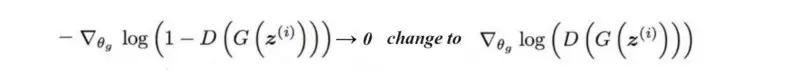
2. Sinh chữ viết tay bằng GAN
Trong phần 2, mình sẽ code một model GAN cơ bản sinh ra chữ viết tay dựa trên MNIST dataset. Code được thực hiện và lưu trên Colab Notebook này.
Đây là một DCGan điển hình, trong generator, mình dùng Transpose Convolution để upsample. Một trong những điểm cần chú ý r sau nhiều lần thực nghiệm, người ta rút ra kinh nghiệm rằng không nên Dropout trong Generator, chỉ dùng trong Discriminator. GAN được định nghĩa có hình dạng tương tự hình minh họa.
Let’s go
from keras.models import Sequential
from keras.layers import *
from matplotlib import pyplot as plt
import numpy as np
import cv2
from numpy.random import randn, randint
import os
from keras.datasets.mnist import load_data as origin_load_data
from keras.optimizers import Adam
from keras.models import Sequential, Model
import tqdm
from sklearn.model_selection import train_test_split
Các hàm phụ trợ:
def load_data():
(x_train, y_train), (x_test, y_test) = origin_load_data()
x_train = (x_train.astype(np.float32) - 127.5)/127.5
x_train = np.expand_dims(x_train, axis=-1)
return (x_train, y_train, x_test, y_test)
# tạo input cho Generator
def gen_z_input(batch_size, latent_dim=100):
z = np.random.normal(0,1, [batch_size, 100])
return z
# tạo ra ảnh fake và label
def gen_fake_image(generator, batch_size):
z = gen_z_input(batch_size)
fake_image = generator.predict(z)
fake_label = gen_label(batch_size, is_real=False)
return fake_image, fake_label
def plot_image(images, n= 5):
for i in range(n * n):
plt.subplot(n, n, 1 + i)
plt.axis('off')
plt.imshow(images[i, :, :, 0], cmap='gray')
plt.show()
def gen_real_image(dataset, batch_size):
ix = randint(0, dataset.shape[0], batch_size)
real_image = dataset[ix]
real_label = gen_label(batch_size, is_real=True)
return real_image, real_label
Model and module. Note: Khi tạo GAN_model mình đã set discriminator.trainable=False, nhưng một số bản Keras discriminator.trainable vẫn là True (-> khiến weights của discriminator vẫn bị update) trong khi bản khác discriminator.trainable=False khi train GAN_model. Vì vậy mình sẽ set lại trainable trong mỗi step
def adam_optimizer():
return Adam(lr=0.0001, beta_1=0.3)
def create_generator(latent_dim=100):
model = Sequential()
model.add(Dense(7*7*512, input_dim=latent_dim, activation='relu'))
new_shape = (7,7,512)
model.add(Reshape(new_shape))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2DTranspose(filters=256, kernel_size=(3,3), padding='same', strides=2, bias=False))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2DTranspose(filters=128, kernel_size=(4,4), padding='same', strides=2, bias=False))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(1, kernel_size=(5,5), strides=1, padding='same', activation='tanh', bias=False))
model.compile(loss='binary_crossentropy', optimizer=adam_optimizer())
return model
def create_discriminator(inp_shape=(28,28,1)):
model = Sequential()
# output: (14*14*512)
model.add(Conv2D(filters=512, kernel_size=(5,5), strides=2, padding='same', input_shape=inp_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.3))
# output: (7*7*64)
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=2, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(filters=128, kernel_size=(3,3), strides=1, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=adam_optimizer(), metrics=['accuracy'])
return model
def create_gan(discriminator, generator):
discriminator.trainable=False
gan_input = Input(shape=(100,))
x = generator(gan_input)
gan_output= discriminator(x)
gan= Model(inputs=gan_input, outputs=gan_output)
gan.compile(loss='binary_crossentropy', optimizer=adam_optimizer())
return gan
# validate discriminator
def val_model(discriminator, generator, val_dataset):
batch_size = 32
real_acc = []
fake_acc = []
for i in range(len(val_dataset)//batch_size-1):
real_image = val_dataset[i:i+1]
z = gen_z_input(batch_size)
fake_image = generator.predict(z)
real_acc.append(discriminator.predict(real_image)[:].mean())
fake_acc.append(discriminator.predict(fake_image)[:].mean())
return np.array(real_acc).mean(), 1- np.array(fake_acc).mean()
def gen_label(size, is_real=True, noise_ratio=0.1):
if is_real:
label = np.ones(size,)*0.9
else:
label = np.ones(size,)*0.1
return np.squeeze(label)
# validate gan model -> đánh giá khả năng đánh lừa discriminator của generator
def val_gan_model(GAN_model, epochs=100):
gan_acc = []
batch_size = 32
for i in range(epochs):
z = np.random.rand(batch_size, 100)
acc = GAN_model.predict(z).mean()
gan_acc.append(acc)
return np.array(gan_acc).mean()
Init Model
x_train, y_train, x_test, y_test = load_data()
train_dataset, val_dataset = x_train, x_test
#init model
generator = create_generator()
discriminator = create_discriminator()
GAN_model = create_gan(discriminator, generator)
Train and plot result. Để có thể control được quá trình train, xác định xem quá trình train có bị hỏng hay không thì phải quan sát dis_acc và gan_acc. Nếu dis_acc quá lớn, nghĩa là discriminator học quá nhanh -> generator không kịp học theo => quá trình train khả năng cao là thất bại. Điều này cũng tương tự như khi dis_acc quá nhỏ, gan_acc quá khác biệt so với dis_acc.
Bạn cần phải điều chính learning_rate, các hệ số trong optimizer và kiến trúc model sao cho khi train, hai thông số dis_acc và gan_acc không quá lệch nhau thì quá trình train mới có khả năng thành công.
epochs=5
batch_size = 8
gan_batch_size = 25
step_per_epoch = len(train_dataset)//batch_size
# vì step_per_epoch quá lớn nên mình quyết định cho nó nhỏ đi
# ---> nhanh được nhìn thấy kết quả hơn
step_per_epoch = step_per_epoch//10
for i in range(epochs):
for step in tqdm.tqdm(range(step_per_epoch)):
real_image, real_label = gen_real_image(train_dataset, batch_size)
z_input = gen_z_input(batch_size)
fake_image = generator.predict(z_input)
fake_label = gen_label(batch_size, is_real=False)
discriminator.trainable=True
discriminator.train_on_batch(real_image, real_label)
discriminator.train_on_batch(fake_image, fake_label)
discriminator.trainable=False
gan_fake_label = gen_label(batch_size, is_real=True)
GAN_model.train_on_batch(z_input, gan_fake_label)
# real_acc, fake_acc = val_model(discriminator, generator, val_dataset)
# dis_acc = (real_acc+ fake_acc)/2
# gan_acc = val_gan_model(GAN_model)
# print("train gan_model: epoch {} step {} ---> dis_acc {}, gan_acc {}".format(i, step, dis_acc, gan_acc))
val_input = gen_z_input(gan_batch_size)
val_image = generator.predict(val_input)
plot_image(val_image)
Dưới đây là kết quả thu được chỉ sau 2p là ta đã thu được những hình trông khá giống chứ viết trong bộ mnist. Chưa thực sự hoàn hảo (do mình ngại đợi lâu) nhưng kết quả này đã chứng minh rằng GAN thực sự hoạt động


Trong bài tiếp theo, mình sẽ hướng dẫn code GAN trên bộ dữ liệu phức tạp hơn 1 chút: bộ dữ liệu khuôn mặt anime. Cảm ơn bạn đã đón đọc