[Image processing] Image Stitching - thuật toán đằng sau công nghệ ảnh Panorama
01 May 2020 - trungthanhnguyen1. Image stitching algorithm
1.1 Introduce

Nguồn ảnh: https://cs205-stitching.github.io
Chắc hẳn mọi người đều đã từng thấy hoặc sử dụng chức năng chụp ảnh panorama của Smart phone. Những tấm ảnh panorama này có kích thước khá lớn, view rộng và với smart phone, ta có thể tạo ra bằng cách lia camera từ từ qua khung cảnh cần chụp. Ứng dụng của lớp bài toán này rất nhiều.
Trước đây khi chất lượng và độ rộng view chụp của các loại camera còn hạn chế, người ta phải dùng các thuật toán để tạo ra các tấm ảnh có độ phân giải cao và có view toàn cảnh từ nhiều ảnh nhỏ.
Tấm ảnh dưới đây từng gây sốt năm 2019, được các bạn hàng xóm Tung Của khoe là tấm ảnh 24.9 tỷ Pixel chụp từ “Vệ tinh với công nghệ lượng tử”, có thể zoom lên từng góc phố, cửa sổ hay con người ở Thượng Hải. Bức ảnh này sau đó được phát hiện rằng nó thực chất chỉ là 1 tấm ảnh được ghép từ hàng chục ngàn bức ảnh do công ty Jingkun Technology tạo nên. Vậy thuật toán / công nghệ đứng đằng sau các tấm ảnh panorama ảo diệu này là gì, hôm nay mình sẽ viết về nó.

Chủ đề này gọi là Image Stitching hay Photo Stitching, kết hợp - ghép 1 tập các ảnh tạo nên 1 ảnh lớn, các ảnh con này có các vùng đè (overlap) lên nhau. Trước đây, người ta làm theo phương pháp “directly minimizing pixel-to-pixel dissimilarities” , tức tìm vùng overlap theo cách so khớp 2 vùng trên 2 ảnh với độ sai khác nhỏ nhất. Tuy nhiên cách này tỏ ra không mấy hiệu quả. Sau đó, hướng giải quyết Feature-based ra đời. Dưới đây là 1 luồng xử lí (Flow) cho bài toán Image Stitching theo hướng Feature-base.
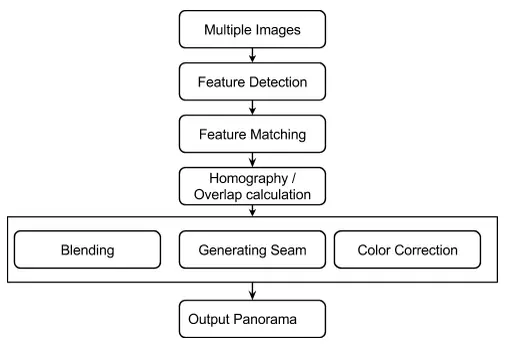
Đây là flow đơn giản dành cho người mới, trong bài này mình sẽ trình bày với trường hợp chỉ có 2 ảnh:
- Sử dụng các thuật toán chuyên biệt để detect tập các keypoint cho từng ảnh. Những keypoint này là những điểm đặc biệt, mang tính chất đặc trưng và không bị ảnh hưởng (hoặc ảnh hưởng ít) bởi độ sáng, các phép xoay, scale (zoom) …
- Tìm cách so khớp (matching) 2 tập keypoint này, tìm ra các cặp keypoint tương ứng.
- Dựa vào các cặp keypoint đó để tìm ra cách biến đổi (transform) -> để ghép 2 ảnh lại với nhau. Như vậy ra đã thu được ảnh panorama.
Note Nghe qua rất đơn giản đúng không. Thực tế, ta còn phải xử lí các tình trạng chênh lệch độ sáng giữa 2 ảnh hay đường nét, màu sắc bị mờ đi ….Để đơn giản hóa nội dung bài này, mình sẽ không viết về các bước hậu xử lí đó.
1.2 Key points detection
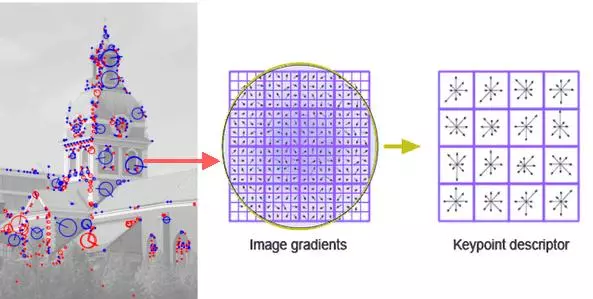
Nếu đã tiếp xúc với các bài toán xử lí ảnh, các bạn sẽ quen với việc sử dụng các Feature extractor như SIFT, SUFT, ORB… Mở màn cho lớp các thuật toán này là SIFT - Scale Invariant Feature Transform. SIFT được dùng để detect các Keypoint trong ảnh. Những keypoint này là những điểm đặc biệt, giàu tính năng và đặc trưng. Với từng Keypoint, SIFT trả về tọa độ (x,y) kèm Descriptor - vector 128 chiều đại diện cho các tính chất đặc trưng của Keypoint đó.
Các Descriptor vector này không/ít bị ảnh hưởng bởi độ xoay, ánh sáng, scale… Điều đó có nghĩa cùng 1 điểm xuất hiện trên 2 ảnh (dù góc chụp, độ sáng khác nhau) sẽ có descriptor xấp xỉ nhau. Hình H1.3 minh họa điều đó.
Trong opencv có cung cấp đầy đủ các Keypoint Extractor SIFT, SUFT, ORB … Code khá đơn giản:
sift = cv2.xfeatures2d.SIFT_create()
kp, des = sift.detectAndCompute(img,None)
Lưu ý: SIFT đã được đăng kí bản quyền. Nếu dùng cho mục đích thương mại cần trả phí hoặc có sự đồng ý của tác giả.
1.3 Key points maching

Giả sử ta đã extract được 2 tập keypoint trên 2 ảnh là $S_1$ = {$k_1, k_2, … k_n$} và $S_2$ = {$k’_1, k’_2, … k’_m$}
Ta cần tiến hành so khớp keypoint trong 2 tập này với nhau, tìm ra các cặp keypoint tương ứng trên 2 ảnh. Người ta thường dùng khoảng cách Euclid giữa 2 Descriptor của 2 keypoint để đo độ sai khác giữa 2 keypoint đó.
Để match 2 tập keypoint với nhau, ta có thể dùng 1 trong 2 thuật toán FLANN maching hoặc Bruce Force Maching. BF Matching có nghĩa là phải tính toán vét cạn, ta phải tính Euclid distance giữa 1 keypoint $k_i$ trong $S_1$ với tất cả các điểm trong $S_2$, từ đó tìm ra các cặp điểm match nhau nhất giữa 2 tập.
FLANN Matching: ngòai BF matching, ta có thể dùng FLANN nếu cần đảm bảo tốc độ, hiệu năng cao. FLANN có nghĩa là “Fast Library for Approximate Nearest Neighbors”, nhanh hơn BF matching, tính toán ít hơn với tư tưởng: đôi khi ta chỉ cần điểm đủ tốt chứ k cần tìm điểm tốt nhất. Cả 2 thuật toán này đều được hỗ trợ bởi Opencv.
BF Matching
match = cv2.BFMatcher()
matches = match.knnMatch(des1,des2,k=2)
FLANN:
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
match = cv2.FlannBasedMatcher(index_params, search_params)
matches = match.knnMatch(des1,des2,k=2)
1.4 Perspectivate transform - estimate homography matrix
1.4.1 Image transformation
Trong xử lí ảnh, các phép biến đổi ảnh như tịnh tiến, xoay, bóp méo, Affine, Perspective transform… được thực hiện bằng cách nhân ma trận trên hệ tọa độ đồng nhất - homogeneous coordinates.
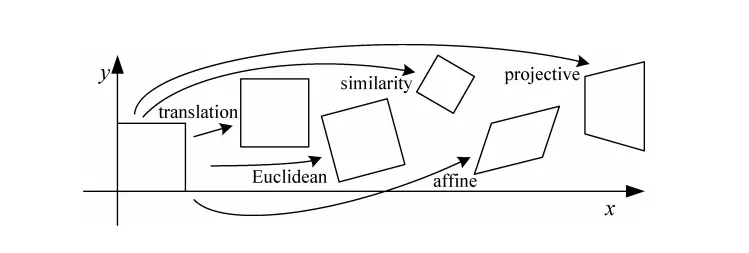
Giả sử 1 điểm ảnh có tọa độ (x,y) sẽ được viết thành (x,y,1). Tọa độ (x,y,1) cũng tương đương với (xz, yz, z). Phép biến đổi 1 ảnh tương đương với việc nhân tọa độ các điểm với 1 ma trận H kích thước 3x3. Chi tiết hơn về Image Transformation có thể đọc tại: Image Alignment. Dưới đây là minh họa về phép transform bằng cách nhân ma trận H trên hệ tọa độ đồng nhất.
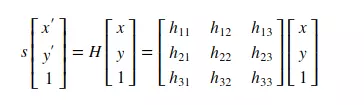
Trong các phép biến đổi ảnh, Perspective transform là 1 phép biến đổi “vi diệu”, nó không bảo toàn góc, độ dài, tính song song… mà chỉ bảo toàn đường thẳng. Cũng nhờ tính chất này, perspective transform giúp chúng ta biến đổi ảnh từ 1 góc chiếu này sang 1 góc chiếu khác hẳn. Nghe hơi khó hiểu nhỉ, hãy nhìn hình minh họa dưới đây.
Tấm ảnh bên trái là ảnh chụp 1 tấm bảng được chụp lệch trái, ảnh bên phải là ảnh biến đổi với perspective transform bằng 1 ma trận H. Ngược lại, nếu ta có sẵn ảnh gốc và ảnh sau biến đổi, ta có thể tính lại được ma trận H.
Trước hết tìm cách detect tọa độ 4 góc của tấm bảng trong hình bên trái, gọi là source_points. Tọa độ tương ứng 4 góc đó trong ảnh bên phải là target_points. Từ 2 tập source_points và target_points, ta hoàn toàn có thể tính được transform matrix H (hormography matrix). Trong trường hợp này, H là 1 Perspective transform matrix. Biến đổi ảnh với H, ta thu được ảnh bên phải, trông có vẻ như được chụp từ góc thẳng vậy, ảo diệu đúng không :D

1.4.2 Estimate homography matrix with RANSAC.
Như vậy, nếu có được 4 điểm trong ảnh input và 4 điểm tương ứng trong ảnh target, ta có thể tính được giá trị từng phần tử trong matrix H. Tuy nhiên, với cách Keypoint matching trong phần 1.3, ta sẽ thu được hằng trăm cặp điểm tương ứng $[(k_1, k’_1), (k_2, k’_2) … (k_n, k’_n)]$. Vậy nên chọn 4 cặp nào trong hằng trăm cặp điểm kia để tính H. Khi đó ta sử dụng thuật toán RANSAC.
RANSAC - Random Sample Consesus, là 1 thuật toán khá đơn giản. Trong bài toán này, RANSAC chỉ đơn giản là lấy mẫu bất kì 4 cặp điểm ngẫu nhiên, tính ra được matrix $H_j$. Với matrix $H_j$ đó, tính độ sai khác giữa các điểm target và các điểm input sau khi biến đổi bằng $H_j$. Ta có công thức
\[Loss = \Sigma^n_0 (disstance(H * k_i, k'_i))\]Trong đó, $k_i$ và $k’_i$ là 1 cặp điểm tương ứng. Lặp lại quá trình lấy mẫu - tính loss này với sô lần đủ lớn. Sau đó chọn $H_j$ có Loss bé nhất. Như vậy ta đã thu được Homography matrix H dùng để biến đổi tọa độ các điểm trong ảnh input sang ảnh target. Opencv có cung cấp cho ta hàm để ước lượng matrix H
H = cv2.findHomography(src_points, dst_points, cv2.RANSAC)
Như vậy ta đã thu được matrix H, dùng để biến đổi tọa độ các điểm trong ảnh input sang tọa độ các điểm tương ứng trong ảnh target với lỗi nhỏ nhất. Khi đó, ảnh input đã được biến đổi/ ghép vào ảnh target tạo ra ảnh panorama. Opencv có hàm tiện cho việc biến đổi ảnh này :
target_img = cv2.warpPerspective(src_img, H_matrix, (w,h))
2. Coding
Nãy giờ lý thuyết hơi nhiều rồi, giờ đến phần code cho trực quan nhé. Mình sẽ code đơn giản hết sức có thể. Để cho tiện, mình code trên Google Colab, mọi người có thể chạy/tải code theo link sau: Google colab notebook: Image stitching.ipynb
# do các bản opencv mới nhất không có SIFT (có bản quyền) nên ta cần down grade openCV
!pip uninstall opencv-python -y
!pip install opencv-contrib-python==3.4.2.17 --force-reinstall
import cv2
import numpy as np
import matplotlib.pyplot as plt
import imutils
import imageio
def plot_img(img, size=(7,7), title=""):
cmap = "gray" if len(img.shape) == 2 else None
plt.figure(figsize=size)
plt.imshow(img, cmap=cmap)
plt.suptitle(title)
plt.show()
def plot_imgs(imgs, cols=5, size=7, title=""):
rows = len(imgs)//cols + 1
fig = plt.figure(figsize=(cols*size, rows*size))
for i, img in enumerate(imgs):
cmap="gray" if len(img.shape) == 2 else None
fig.add_subplot(rows, cols, i+1)
plt.imshow(img, cmap=cmap)
plt.suptitle(title)
plt.show()
src_img = imageio.imread('http://www.ic.unicamp.br/~helio/imagens_registro/foto1A.jpg')
tar_img = imageio.imread('http://www.ic.unicamp.br/~helio/imagens_registro/foto1B.jpg')
src_gray = cv2.cvtColor(src_img, cv2.COLOR_RGB2GRAY)
tar_gray = cv2.cvtColor(tar_img, cv2.COLOR_RGB2GRAY)
plot_imgs([src_img, tar_img], size=8)

SIFT_detector = cv2.xfeatures2d.SIFT_create()
kp1, des1 = SIFT_detector.detectAndCompute(src_gray, None)
kp2, des2 = SIFT_detector.detectAndCompute(tar_gray, None)
## Match keypoint
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=False)
## Bruce Force KNN trả về list k ứng viên cho mỗi keypoint.
rawMatches = bf.knnMatch(des1, des2, 2)
matches = []
ratio = 0.75
# giữ lại các cặp keypoint sao cho với kp1, khoảng cách giữa kp1 với
# ứng viên 1 nhỏ hơn nhiều so với khoảng cách giữa kp1 và ứng viên 2
for m,n in rawMatches:
if m.distance < n.distance * 0.75:
matches.append(m)
# do có cả nghìn match keypoint,
# ta chỉ lấy tầm 100 -> 200 cặp tốt nhất để tốc độ xử lí nhanh hơn
matches = sorted(matches, key=lambda x: x.distance, reverse=True)
matches = matches[:200]
img3 = cv2.drawMatches(src_img, kp1, tar_img, kp2, matches, None,flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plot_img(img3, size=(15, 10))
#ta thấy các cặp Keypoint giữa 2 ảnh đã được match khá chính xác
#số điểm nhiễu không quá nhiều

Estimate Homography matrix and Transform Image
kp1 = np.float32([kp.pt for kp in kp1])
kp2 = np.float32([kp.pt for kp in kp2])
pts1 = np.float32([kp1[m.queryIdx] for m in matches])
pts2 = np.float32([kp2[m.trainIdx] for m in matches])
# estimate the homography between the sets of points
(H, status) = cv2.findHomography(pts1, pts2, cv2.RANSAC)
print(H)
=> [[ 7.74666572e-01 2.97937348e-02 4.48576839e+02]
[-1.31635664e-01 9.10804272e-01 7.63230050e+01]
[-2.03305884e-04 -3.33235166e-05 1.00000000e+00]]
Transform image
h1, w1 = src_img.shape[:2]
h2, w2 = tar_img.shape[:2]
result = cv2.warpPerspective(src_img, H, (w1+w2, h1))
result[0:h2, 0:w2] = tar_img
plot_img(result, size=(20,10))

Như vậy, chỉ với vài dòng code ta đã có thể ghép 2 ảnh lại với nhau. Ảnh kết quả nhìn cũng khá hợp lý đúng không. Thực ra nếu để ý kĩ, màu sắc giữa 2 phần được ghép vào nhìn có chút sai khác nhau. Trong thực tế, người ta phải dùng các phương pháp hậu xử lí để khắc phục tình trạng này. Tuy nhiên do thời lượng bài viết mình xin phép dừng lại tại đây. Cảm ơn các bạn đã đọc bài viết :D
Hãy tham gia group: Vietnam Ai Llink Sharing để được tiếp cận các bài viết hay nhất :) .