[Speech] p1. Cơ bản về xử lí giọng nói
01 Apr 2020 - trungthanhnguyen
Mình dự định viết series tối thiểu 2 phần nhằm cung cấp các kiến thức nền tảng trong xử lý tiếng nói. Trong phần này mình sẽ viết trọng tâm vào lý thuyết âm thanh và ngữ âm học. Có thể bạn sẽ thấy nhàm chán, nhưng nếu muốn đào sâu hơn và phát triển trong lĩnh vực “xử lý tiếng nói”, ta cần có những kiến thức nền tảng vững chắc thay vì đọc qua loa vài thuật toán, paper nhỏ lẻ.
1. Nguyên lý hình thành tiếng nói.
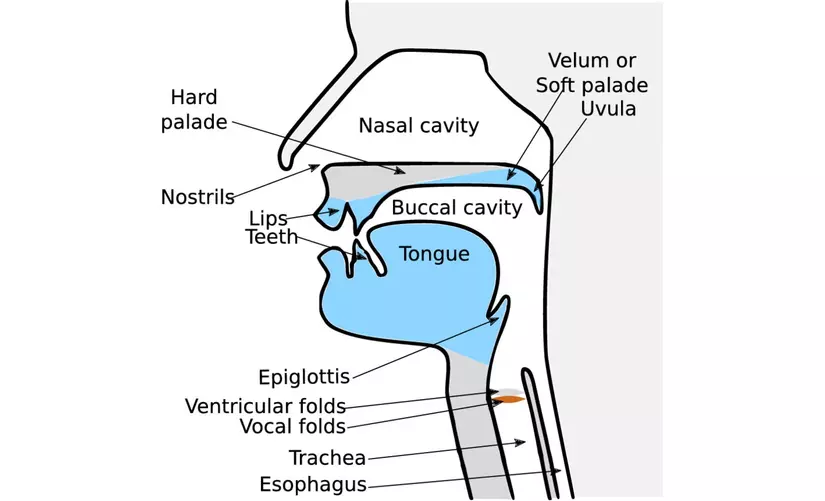
Đầu tiên, một luồng hơi được đẩy lên từ phổi tạo áp lực lên thanh quản (Vocal folds). Dưới áp lực đó, thanh quản mở ra giúp luồng không khí thoát qua, áp lực giảm xuống khiến thanh quản tự động đóng lại. Việc đóng lại như vậy lại khiến áp lực tăng lên và quá trình tái diễn. Các chu kì đóng/mở thanh quản này liên tục tái diễn, tạo ra các tần số sóng âm với tần số cơ bản khoảng 125Hz với nam, 210Hz với nữ. Đó là lí do giọng của nữ giới thường có xu hướng cao hơn giọng nam. Tần số này gọi là fundamental frequency F0.
Như vậy thanh quản đã tạo ra các tần số sóng âm cơ bản. Tuy nhiên để hình thành lên tiếng nói còn cần đến các cơ quan khác như: vòm họng, khoang miệng, lưỡi, răng, môi, mũi… Các cơ quan này hoạt động như 1 bộ “cộng hưởng” giống hộp đàn guitar, nhưng có khả năng thay đổi hình dạng linh hoạt. Bộ cộng hưởng này có tác dụng khuếch đại 1 vài tần số, triệt tiêu một vài tần số khác để tạo ra âm thanh. Khả năng thay đổi hình dạng linh hoạt của nó giúp tạo ra các âm thanh khác nhau để hình thành lên tiếng nói.
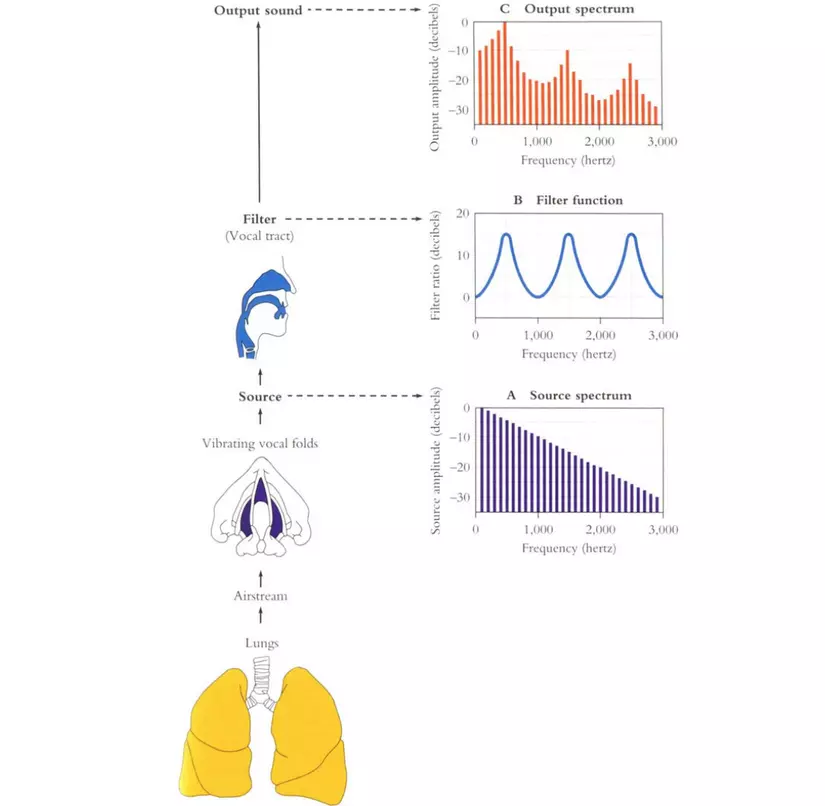
Hình ảnh trên đây mô tả rất chi tiết về cơ chế này. Source + Filter $\longrightarrow$ Output sound . Tại spectrum của output sound, ta thấy có 3 đỉnh, các đỉnh này lần lượt gọi là đỉnh F1, F2, F3 …hay còn gọi là các formant. Giá trị, vị trí, sự thay đổi theo thời gian của các đỉnh này đặc trưng cho các âm vị. Trong các phương pháp nhận dạng tiếng nói truyền thống, người ta sẽ cố gắng tách thông tin về các formant này ra khỏi F0 rồi mới sử dụng thông tin này để nhận dạng.
1.1 Âm vô thanh và hữu thanh (optional)
Có 2 loại âm thanh được tạo ra ở quá trình trên là âm vô thanh và hữu thanh. Để dễ hình dung, hãy đặt tay lên cổ họng và phát âm /b/, bạn sẽ cảm nhận được sự rung của cổ họng, đó là âm hữu thanh. Tương tự, khi phát âm /th/, ta không cảm thấy sự rung này, đó là âm vô thanh.
2. Âm, âm tiết, âm vị
2.1 Âm tiết
Trong tiếng Anh và nhiều ngôn ngữ khác, 1 từ được ghép bởi nhiều âm tiết. VD từ “want” có 1 âm tiết, “wanna” có 2 âm tiếng, “computer” có 3 âm tiết …. Trong khi đó trong tiếng Việt, gần như mọi âm tiết đều mang ngữ nghĩa nên ta có thể coi âm tiết là 1 từ. Một âm tiết thường là một nguyên âm, có hoặc không có các phụ âm đi kèm.
Nguyên âm: Tiếng anh là vowel, là những âm thanh được phát ra mà không có sự cản trở trong đường hô hấp, không bị ngắt quãng. Trong tiếng Việt có các nguyên âm: a, o, e, i, u … Để hình dung, bạn thử đọc chữ /a/ kéo dài xem, ta có thể tạo ra tiếng /a/ liên tục, không có sự ngắt quãng nào.
Phụ âm: Tiếng Anh là consonants, khác với nguyên âm, phụ âm được tạo ra với sự đóng hoàn toàn hoặc 1 phần của thanh quản, làm phá vỡ, ngắt quãng dòng nguyên âm, tạo ra những khoảng ngắt quãng rõ ràng. Hãy thử đọc 1 câu đã lược bỏ tất cả phụ âm, bạn sẽ thấy mình chỉ ú ớ như 1 đứa vừa đi khám răng về.
2.2 Âm vị và âm (phoneme and phone)
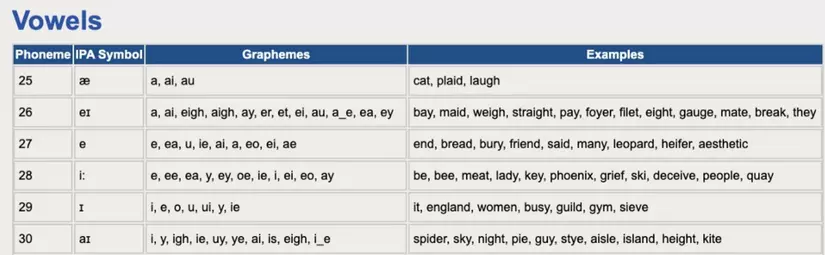
Âm vị: Tiếng anh là phoneme, trong nhiều loại ngôn ngữ, một kí tự/cụm kí tự (letter) trong các từ khác nhau có thể có nhiều cách phát âm khác nhau. Bảng chữ cái latinh có 26 chữ cái nhưng có tới 44 phoneme. VD chữ “ough” trong câu sau có tới 4 kiểu phát âm: Though I coughed roughly and hiccoughed throughout the lecture
Trong các bài toán Text to Speech, người ta cần chuyển đổi từ dạng chữ viết sang dạng chuỗi các âm vị. Chữ tiếng Việt của chúng ta có tính tượng thanh cao hơn, có tính thống nhất cao giữa cách viết và cách đọc. Đó có thể là 1 thuận lợi của chúng ta khi làm việc với tiếng Việt.
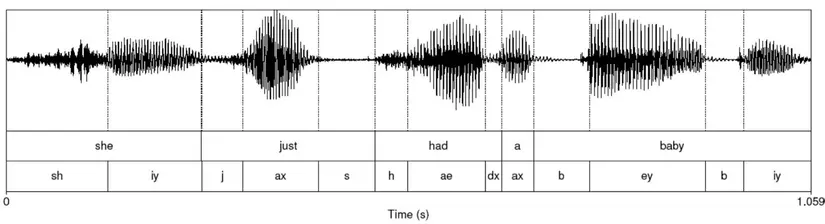
Âm: Tiếng anh là phone là sự hiện thực hoá âm vị. Cùng 1 phoneme nhưng mỗi người lại có 1 giọng đọc khác nhau, VD cùng từ “ba” nhưng giọng nam khác giọng nữ, giọng người A khác giọng người B. Để dễ phân biệt giữa “phoneme” và “phone” thì bạn có thể quan sát hình dưới đây. Hình ảnh mô tả câu “she just had a baby” được tách thành các âm vị (phoneme) ở hàng dưới và được hiện thực hoá thành các “phone” (hình ảnh các sóng âm thanh).
Trong lĩnh vực nhận dạng giọng nói, ta có tập dataset TIMIT - 1 tập các đoạn đọc được phiên âm và căn chỉnh (align) thời gian của 630 người Mỹ. Tập dữ liệu được thu thập và annotate bởi các chuyên gia về ngữ âm học, từng âm được nghe và đánh dấu vị trí mở đầu và kết thúc rõ ràng.
3. Cơ chế nghe
Trong nhận dạng giọng nói, việc hiểu được cơ chế “nghe” của con người quan trọng hơn cách “nói”
Âm thanh, tiếng nói mà chúng ta vẫn nghe hằng ngày là 1 pha trộn của rất nhiều sóng với các tần số khác nhau. Các tần số này thường nằm trong khoảng từ 20Hz -> 20000Hz. Tuy nhiên tai người (và các loài động vật) hoạt động phi tuyến tính, tức không phải rằng độ cảm nhận âm thanh 20000Hz sẽ gấp 1000 lần âm thanh 20Hz. Thường thì tai người rất nhạy cảm ở âm thanh tần số thấp, kém nhạy cảm ở tần số cao.
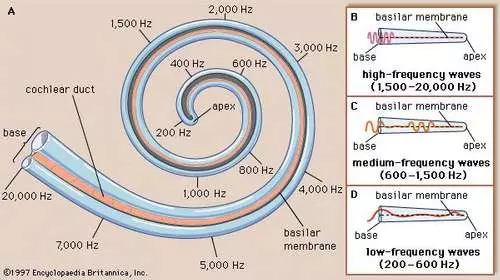
Khi âm thanh truyền tới tai va đập vào màng nhĩ, màng nhĩ rung lên, truyền rung động lên 3 ba xương nhỏ: malleus, incus, stapes tới ốc tai. Ốc tai là 1 bộ phận dạng xoắn, rỗng như 1 con ốc. Ốc tai chứa các dịch nhầy bên trong giúp truyền âm thanh, dọc theo ốc tai là các tế bào lông cảm nhận âm thanh. Các tế bào lông này rung lên khi có sóng truyền qua và gửi tín hiệu tới não bộ. Các tế bào ở đoạn đầu cứng hơn, rung động với các tần số cao. Càng sâu vào trong, các tế bào càng bớt cứng, đáp ứng các tần số thấp. Do cấu tạo ốc tai cùng số lượng các tế bào đáp ứng tần số thấp chiếm phần lớn khiến cho việc cảm nhận của tai người (và động vật) là phi tuyến tính, nhạy cảm ở tần số thấp, kém nhạy cảm ở tần số cao.
Trong xử lí tiếng nói, ta cần 1 cơ chế để map giữa tín hiệu âm thanh thu được bằng cảm biến và độ cảm nhận của tai người. Việc map này được thực hiện bởi Mel filterbank, ta sẽ nói chi tiết về Mel filterbank ở phần sau, khi đã được trang bị đủ kiến thức nền tảng
4. Fourier Transform
Một mảng kiến thức không thể thiếu khi làm việc với tín hiệu âm thanh là xử lí tín hiệu số, trọng tâm là Fourier transform (hay còn gọi là biến đổi Fourier).
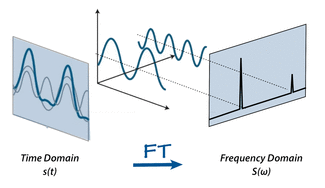
Âm thanh là 1 chuỗi tín hiệu rất dài, nhưng hàm lượng thông tin trong đó không nhiều. Để lấy mẫu 1 đoạn âm thanh đảm bảo chất lượng, bạn cần lấy mẫu với tần số khoảng 16000Hz. Như vậy chỉ 1 giây âm thanh, input của bạn là 1 array gồm 16000 giá trị. Thật không phù hợp với các mô hình machine learning, deep learning đúng không.
Như mình đã nói ở trên rằng âm thanh được kết hợp từ các sóng có tần số khác nhau, vậy hãy suy nghĩ ngược lại, tại sao ta không tìm cách phân giải 1 đoạn âm thanh ngắn thành các sóng với tần số và biên độ cụ thể. Điều đó được minh hoạ khá dễ hiểu bằng hình trên đây. Trong hình, 1 đoạn âm thanh trong miền thời gian được kết hợp từ 2 sóng tuần hoàn. Do 2 sóng này có tính chất tuần hoàn, thay vì phải lưu giá trị theo thời gian, ta chỉ cần lưu lại tần số, biên độ và pha giao động của các sóng này. Ta có 1 denser representation cho đoạn âm thanh đó (1 cách biểu diễn giàu thông tin hơn).
Như vậy, với Fourier Transfrom, ta đã chuyển đổi thông tin từ miền thời gian sang miền tần số. Ngược lại, ta có inverse Fourier transform (biến đổi Fourier ngược) để chuyển đổi thông tin từ miền tần số về miền thời gian. Fourier transform có ứng dụng rất lớn trong lĩnh vực xử lí tín hiệu (âm thanh, ảnh, thông tin) … Nếu có thời gian, bạn nên đọc thêm về Fourier Transform.
Công thức Fourier Transform cho hàm liên tục:
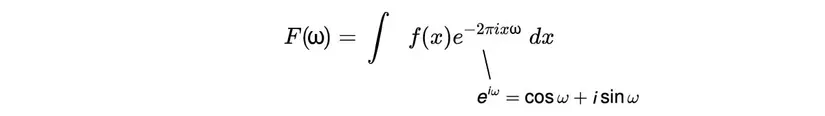
Công thức biến đổi Fourier hàm rời rạc (DFT - discrete fourier transform):
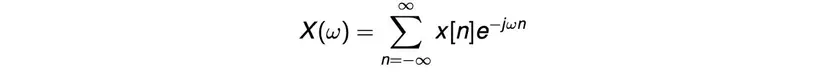
Biến đổi Fourier là 1 biến đổi symmetrical (đối xứng), tức 1 thông tin được biến đổi Fourier từ miền thời gian sang miền tần số, ta có thể biến đổi Fourier ngược để khôi phục thông tin từ miền tần số lại về miền thời gian. Dưới đây là 1 minh hoạ 1 sóng vuông được phân giải thành các sóng Sin. Có thể thấy với giá trị N càng cao, độ chính xác càng lớn.
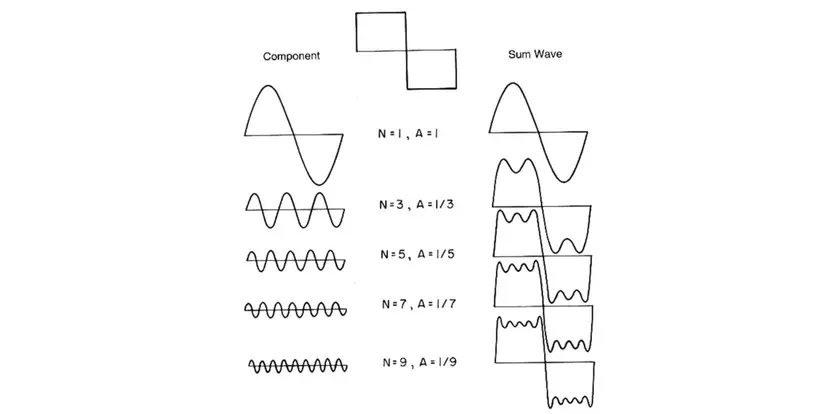
Trong các thuật toán hiện nay, thay vì dùng thuật toán DFT gốc, người ta dùng FFT (Fast Fourier Transform) 1 thuật toán hiệu quả và nhanh để tăng tốc độ tính toán. Như vậy tới đây, ta đã hiểu cơ bản rằng tín hiệu âm thanh gốc sẽ được biến đổi Fourier sang miền tần số rồi mới dùng để tính toán. Sang phần sau mình sẽ nói rõ hơn.
Phần này hơi nhiều lý thuyết nhàm chán nên chắc mọi người không hứng thú lắm nhỉ, phần tiếp theo mình sẽ đi sâu vào việc trích xuất thông tin Feature extraction và lý thuyết về Mel Frequency Cepstral Coefficients (MFCC). Cảm ơn mọi người đã đọc.
Phần 2: Feature Extraction - MFCC cho xử lí giọng nói